
For more information, please see:
– This 20min presentation: 2019 – Part 3: “We see things not as they are, but as we are”.
– A paper on this work I presented at SIGGraph 2019
– For a much deeper conceptual and technical analysis, please see Chapter 5 of my PhD Thesis.
Learning to See is an ongoing collection of works that use machine learning algorithms to reflect on ourselves and how we make sense of the world. The picture we see in our conscious mind is not a mirror image of the outside world, but is a reconstruction based on our expectations and prior beliefs.
An artificial neural network looks out onto the world, and tries to make sense of what it is seeing. But it can only see through the filter of what it already knows.
Just like us.
Because we too, see things not as they are, but as we are.
In this context, the term seeing, refers to both the low level perceptual and phenomenological experience of vision, as well as the higher level cognitive act of making meaning, and constructing what we consider to be truth. Our self affirming cognitive biases and prejudices, define what we see, and how we interact with each other as a result, fuelling our inability to see the world from each others’ point of view, driving social and political polarization. The interesting question isn’t only “when you and I look at the same image, do we see the same colors and shapes”, but also “when you and I read the same article, do we see the same story and perspectives?”.
Everything that we see, read, or hear, we try to make sense of by relating to our own past experiences, filtered by our prior beliefs and knowledge.
In fact, even these sentences that I’m typing right now, I have no idea, what any of it means to you. It’s impossible for me to see the world through your eyes, think what you think, and feel what you feel, without having read everything that you’ve ever read, seen everything that you’ve ever seen, and lived everything that you’ve ever lived.
Empathy and compassion are much harder than we might realize, and that makes them all the more valuable and essential.
Learning to see: Gloomy Sunday (2017)
2017. HD Video. Duration: 3:02. Technique: Custom software, Artificial Intelligence, Machine Learning, Deep Learning, Generative Adversarial Networks.
Learning to See: interactive edition (2017)
2017. Materials: Custom software, PC, camera, projection, cables, cloth, wires. Technique: Custom software, Artificial Intelligence, Machine Learning, Deep Learning, Generative Adversarial Networks.
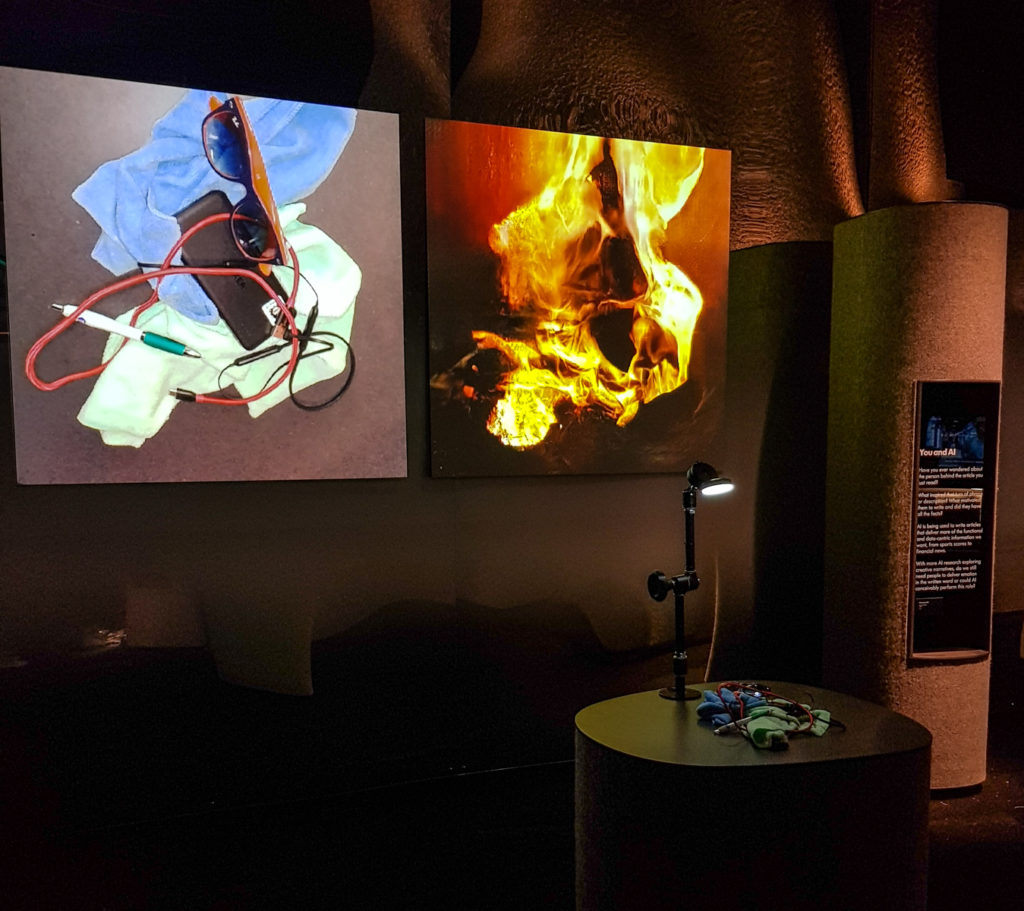
This particular edition is an interactive installation in which a number of neural networks analyse a live camera feed pointing at a table covered in everyday objects. Through a very tactile, hands-on experience, the audience can manipulate the objects on the table with their hands, and see corresponding scenery emerging on the display, in realtime, reinterpreted by the neural networks. Every 30 seconds the scene changes between different networks trained on five different datasets: (the four natural elements:) ocean & waves (representing ‘water’), clouds & sky (representing ‘air’), fire, flowers (representing earth, and life); and images from the Hubble Space telescope (representing the universe, cosmos, quintessence, aether, the void, the home of God). The interaction can be a very short, quick, playful experience. Or the audience can spend hours, meticulously crafting their perfect nebula, or shaping their favourite waves, or arranging a beautiful bouquet.
Installation view at “Creative Machines”, Taikang Art Museum, Beijing, 2024

Installation view at “AI: More than Human”, The Barbican, London, UK, 2019





Learning to see: We are made of star dust (2017)
2017. HD Video. Duration: 2:53. Technique: Custom software, Artificial Intelligence, Machine Learning, Deep Learning, Generative Adversarial Networks.
Learning to see: True Colors (2020)
2020. HD Video. Duration: 1:00. Technique: Custom software, Artificial Intelligence, Machine Learning, Deep Learning, Generative Adversarial Networks.
Earlier studies
Related work
- Learning to Dream
- Learning to Dream: Supergan!
- Learning to See: Hello, World!
- Dirty Data
- FIGHT!
- All watched over by machines of loving grace. Deepdream edition
- Keeper of our collective consciousness
Related texts
- All watched over by machines of loving grace
- A digital god for a digital culture. Resonate 2016
- Deepdream is blowing my mind
Background
Originally loosely inspired by the neural networks of our own brain, Deep Learning Artificial Intelligence algorithms have been around for decades, but they are recently seeing a huge rise in popularity. This is often attributed to recent increases in computing power and the availability of extensive training data. However, progress is undeniably fueled by multi-billion dollar investments from the purveyors of mass surveillance – technology companies whose business models rely on targeted, psychographic advertising, and government organizations focussed on the War on Terror. Their aim is the automation of Understanding Big Data, i.e. understanding text, images and sounds. But what does it mean to ‘understand’? What does it mean to ‘learn’ or to ‘see’?
These images are not using ‘style transfer‘. In style transfer, the network is generally run on, and contains information on, a single image. These networks contain knowledge of the entire dataset, hundreds of thousands of images. Having been trained on these datasets, when the networks look at the world, they can only see through the filter of what they have seen before.
Source code and publication
I released an opensource demo which is the foundation for this and many of the Learning to see works. The demo allows live realtime preprocessing of a camera input (such as a webcam) fed into a neural network for live realtime inference.
The source and example pretrained models can be downloaded at:
https://github.com/memo/webcam-pix2pix-tensorflow
I also presented a paper at SIGGraph 2019 which can be found at:
https://dl.acm.org/doi/10.1145/3306211.3320143
Acknowledgements
Created during my PhD at Goldsmiths, University of London, funded by the EPSRC.