2018. Medium: Live improvisational performance with human singer and AI, live generative visuals and audio (duration: 20-40mins).
Technique: Custom software, generative video, generative audio, Artificial Intelligence, Machine Learning, Generative Adversarial Networks, Variational Autoencoders.
Excerpts from performance at ASSEMBLY 2018, Somerset House Studios
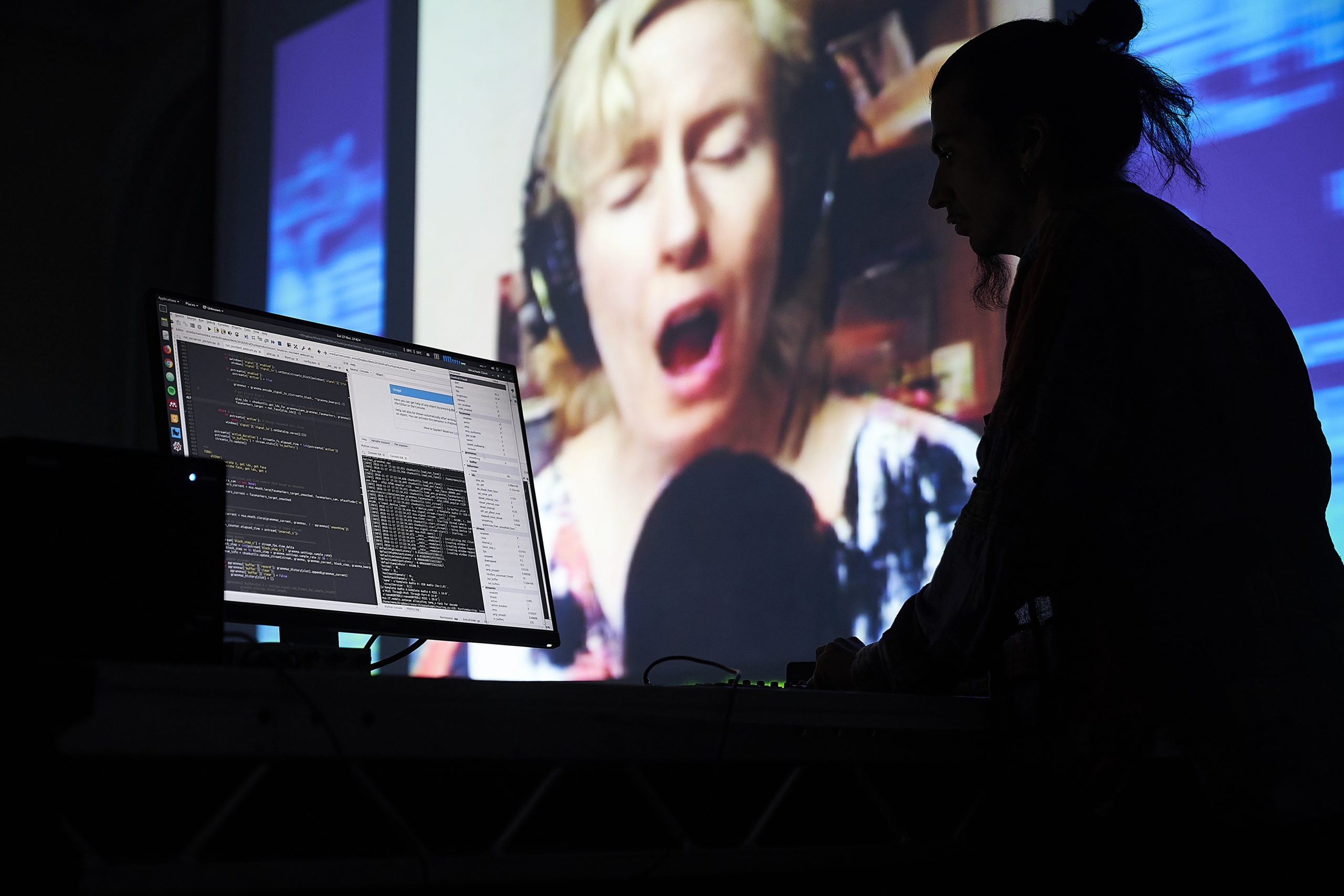
ULTRACHUNK is a collaboration between performer Jennifer Walshe, and artist Memo Akten. At once surreal, spellbinding and deeply alarming, ULTRACHUNK is a live improvisational duet between a classically trained musician and her AI doppelganger. It is one of the first—if not the first—live performances where the images and sounds are entirely generated by artificial neural networks in real-time (rather than playing back pre-generated AI samples, as other artists were exploring at the time). And crucially, it did so interactively, responding to a live human performer.
This work continues my research into large artificial neural networks as systems for real-time, expressive human-computer interaction, framing them as new kinds of instruments that can emerge through meaningful human control.
It also continues my research into data sovereignty. As models grew larger, they demanded ever more training data, and acquiring such vast datasets raised ethical, legal, and even spiritual questions. For this project, we asked how we might create all of our own training material—and our answer was ritual. Over the course of a year, Irish vocalist and composer Jennifer Walshe engaged in a daily ritual of solo improvisations in front of her webcam, wherever she happened to be in the world. Using the many hours of video and audio, I built and trained a machine-learning driven live performance system comprising multiple custom architectures and models.
During the performance, the video and audio output from the machine are neither recordings nor processed—every frame and sound is synthesized live in real-time, navigating the latent hypersphere, constructed from the fragments of memories in the depths of multiple neural networks. The original and virtual Walshe inhabit the Uncanny Valley together, singing in duet, improvising, listening and responding to each other.
Due to the improvisational (and unpredictable) nature of the performance, the duration varies and is usually 20-40 minutes.